
18-May-2017 Parameter estimation
Often we collect a sample of data not to make statements about that particular sample but to generalize our statements to say something about the population. Estimation is the process of making inferences about an unknown population parameter from a random sample drawn from the population of interest. An estimator is a method for arriving at an estimate of the value of an unknown parameter. Often there are many competing estimators for the population parameter that differ based on the underlying statistical theory.
Point estimate
A point estimate is the best estimate, in some sense, of the population parameter. The most well-known estimator is the sample mean which produces an estimate of the population mean.
It should be obvious that any point estimate is not absolutely accurate. It is an estimate based on only a single random sample. If repeated random samples were taken from the population the point estimate would be expected to vary from sample to sample. This leads to the definition of an interval estimator which provides a range of values defined by the limits [L, U].
Confidence interval
A confidence interval defines limits [L, U] constructed on the basis that a specified proportion of the confidence intervals include the true parameter in repeated sampling. How frequently the confidence interval contains the parameter is determined by the confidence level. 95% is commonly used and means that in repeated sampling 95% of the confidence intervals include the parameter. 99% is sometimes used when more confidence is needed and means that in repeated sampling 99% of the intervals include the parameter. It is unusual to use a confidence level of less than 90% as too many intervals would fail to include the parameter.
Again a confidence interval is formed using an interval estimator based on statistical theory and assumptions about the underlying population. The t-based confidence interval estimator for a population mean is an example taught in most introductory textbooks.
Many people misunderstand confidence intervals. A confidence interval is a frequentist concept, that is, the probability is defined in a series of repetitions of an experiment. A confidence interval does not predict with a given probability that the parameter lies within the interval. The problem arises because the word confidence is misinterpreted as implying probability. After drawing a sample and forming a confidence interval, it either does contain the population parameter or it doesn’t. This is the same as how the probability of obtaining a head or tails in the toss of fair coin is 50%, but after a toss has happened it is either a head or tail (the predicted event happened or it didn’t). Similarly, the 95% probability associated with a 95% confidence interval only applies to the method used to construct the interval, not to the individual realized intervals.
As an example, let’s say we draw a single random sample and construct a 95% confidence interval for the mean that results in an interval [15, 20]. We could say “We are 95% confident the population mean is between 15 and 20”. It would be incorrect to say “There is a 95% probability the population mean is between 15 and 20”. The switch here is a subtle change of the word confident to the word probability. The word confident means that the estimation method works 95% of the time, the other 5% of the time it is wrong.
Illustration
We can illustrate these concepts with a Monte-Carlo simulation.
Let’s assume the population has a mean μ=0 and standard deviation σ=1, and we draw 100 random samples from the population each with a size n=40, then compute the 95% mean confidence interval for each sample.
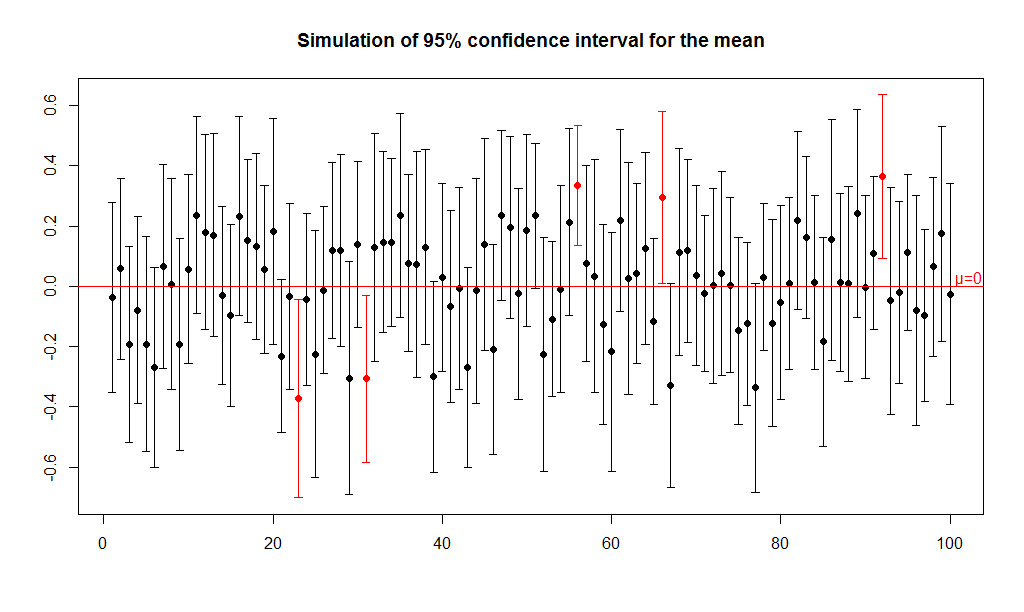
The plot shows the limits of the confidence interval as an error bar, with the mean as a dot, for each of 100 samples. The horizontal red line indicates μ=0, the true population mean. Highlighted in red are repetitions where the mean confidence interval does not include μ=0. You can see that 5/100=5% are colored red and 95/100=95% are colored black, and therefore interval included the population mean 95% of the time. Proof that our estimation method works 95% of the time!
Reporting results
A point estimate of the parameter from a single sample is not a great way to present your findings. It gives no idea about uncertainty. A point estimate with a confidence interval provides more information, as the point estimate is the most likely value given the sample observed and the confidence interval expresses the uncertainty in this estimate. If the width of the confidence interval is large you should have less confidence in the estimate, and if the interval is narrow you can have more confidence. When the interval is wide you could repeat the experiment with a larger sample size to get a narrower interval. Repeating an experiment is always a good way to confirm that your results are real and is key to making good scientific judgments.
Related links:
A great interactive visualization of the confidence interval: http://rpsychologist.com/d3/CI/
Comments
Comments are now closed.