
Compare Groups examines independent samples and makes inferences about the differences between them.
Independent samples occur when observations are made on different sets of items or subjects. If the values in one sample do not tell you anything about the values in the other sample, then the samples are independent. If the knowing the values in one sample could tell you something about the values in the other sample, then the samples are related.
Use univariate descriptive statistics to describe a quantitative variable that is classified by a factor variable.
Side-by-side univariate plots summarize the distribution of data stratified into groups.
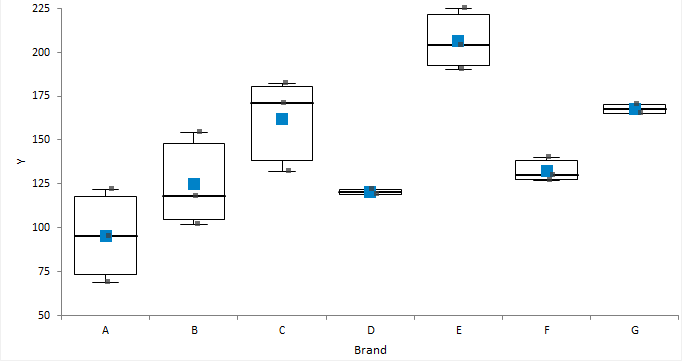
Summarize the distribution of a single quantitative variable stratified into groups.
An equality hypothesis test formally tests if two or more population means/medians are different.
When the test p-value is small, you can reject the null hypothesis and conclude that the populations differ in means/medians.
Tests for more than two samples are omnibus tests and do not tell you which groups differ from each other. You should use multiple comparisons to make these inferences.
An equivalence hypothesis test formally tests if two population means are equivalent, that is, practically the same.
An equality hypothesis test can never prove that the means are equal, it can only ever disprove the null hypothesis of equality. It is therefore of interest when comparing say a new treatment against a placebo, where the null hypothesis (assumption of what is true without evidence to the contrary) is that the treatment has no effect, and you want to prove the treatment produces a useful effect. By contrast, an equivalence hypothesis test is of interest when comparing say a generic treatment to an existing treatment where the aim is to prove that they are equivalent, that is the difference is less than some small negligible effect size. A equivalence hypothesis test therefore constructs the null hypothesis of non-equivalence and the goal is to prove the means are equivalent.
The null hypothesis states that the means are not equivalent, against the alternative hypothesis that the difference between the means is within the bounds of the equivalence interval, that is, the effect size is less than some small difference that is considered practically zero. The hypothesis is tested as a composite of two one-sided t-tests (TOST), H01 tests the hypothesis that mean difference is less than the lower bound of the equivalence interval, test H02 that the mean difference is greater than the upper bounds of the equivalence interval. The p-value is the greater of the two one sided t-test p-values. When the test p-value is small, you can reject the null hypothesis and conclude the samples are from populations with practically equivalent means.
Tests for the equality/equivalence of means/medians of independent samples and their properties and assumptions.
| Test | Purpose |
|---|---|
| Z | Test if the difference between means is equal to a hypothesized value when the population standard deviation is known. |
| Student's t | Test if the difference between means is equal to a hypothesized value. Assumes the populations are normally distributed. Due to the central limit theorem, the test may still be useful when this assumption is not true if the sample sizes are equal, moderate size, and the distributions have a similar shape. However, in this situation the Wilcoxon-Mann-Whitney test may be more powerful. Assumes the population variances are equal. This assumption can be tested using the Levene test. The test may still be useful when this assumption is not true if the sample sizes are equal. However, in this situation, the Welch t-test may be preferred. |
| Welch t | Test if the difference between means is equal to a hypothesized value. Assumes the populations are normally distributed. Due to the central limit theorem, the test may still be useful when this assumption is not true if the sample sizes are equal, moderate size, and the distributions have a similar shape. However, in this situation the Wilcoxon-Mann-Whitney test may be more powerful. Does not assume the population variances are equal. |
| TOST (two-one-sided t-tests) | Test if the means are equivalent. Assumes the populations are normally distributed. Due to the central limit theorem, the test may still be useful when this assumption is not true if the sample sizes are equal, moderate size, and the distributions have a similar shape. Note: The TOST can be performed using either a
Student's t-test or Welch t-test.
|
| ANOVA | Test if two or means are equal. Assumes the populations are normally distributed. Due to the central limit theorem, the test may still be useful when this assumption is not true if the sample sizes are equal and moderate size. However, in this situation the Kruskal-Wallis test is may be more powerful. Assumes the population variances are equal. This assumption can be tested using the Levene test. The test may still be useful when this assumption is not true if the sample sizes are equal. However, in this situation, the Welch ANOVA may be preferred. |
| Welch ANOVA | Test if two or more means are equal. Assumes the populations are normally distributed. Due to the central limit theorem, the test may still be useful when this assumption is not true when the sample sizes are equal and moderate size. The Kruskal-Wallis test may be preferable as it is more powerful than Welch's ANOVA. Does not assume the population variances are equal. |
| Wilcoxon-Mann-Whitney | Test if there is a shift in location. When the population distributions are identically shaped, except for a possible shift in central location, the hypotheses can be stated in terms of a difference between means/medians. When the population distributions are not identically shaped, the hypotheses can be stated as a test of whether the samples come from populations such that the probability is 0.5 that a random observation from one group is greater than a random observation from another group. |
| Kruskal-Wallis | Test if two or more medians are equal. Assumes the population distributions are identically shaped, except for a possible shift in central location. |
Test if there is a difference between the means/medians of two or more independent samples.
Test if there is equivalence of the means of two independent samples.
An effect size estimates the magnitude of the difference between two means/medians.
The term effect size relates to both unstandardized measures (for example, the difference between group means) and standardized measures (such as Cohen's d; the standardized difference between group means). Standardized measures are more appropriate than unstandardized measures when the metrics of the variables do not have intrinsic meaning, when combining results from multiple studies, or when comparing results from studies with different measurement scales.
A point estimate is a single value that is the best estimate of the true unknown parameter; a confidence interval is a range of values and indicates the uncertainty of the estimate.
Estimators for the difference in means/medians of independent samples and their properties and assumptions.
| Estimator | Purpose |
|---|---|
| Mean difference | Estimate the difference between the means. |
| Standardized mean difference | Estimate the standardized difference between the means. Cohen's d is the most popular estimator using the difference between the means divided by the pooled sample standard deviation. Cohen's d is a biased estimator of the population standardized mean difference (although the bias is very small and disappears for moderate to large samples) whereas Hedge's g applies an unbiasing constant to correct for the bias. |
| Hodges-Lehmann location shift | Estimate the shift in location. A shift in location is equivalent to a difference between means/medians when the distributions are identically shaped. |
Estimate the difference between the means/medians of 2 independent samples.
Multiple comparisons make simultaneous inferences about a set of parameters.
When making inferences about more than one parameter (such as comparing many means, or the differences between many means), you must use multiple comparison procedures to make inferences about the parameters of interest. The problem when making multiple comparisons using individual tests such as Student's t-test applied to each comparison is the chance of a type I error increases with the number of comparisons. If you use a 5% significance level with a hypothesis test to decide if two groups are significantly different, there is a 5% probability of observing a significant difference that is simply due to chance (a type I error). If you made 20 such comparisons, the probability that one or more of the comparisons is statistically significant simply due to chance increases to 64%. With 50 comparisons, the chance increases to 92%. Another problem is the dependencies among the parameters of interest also alter the significance level. Therefore, you must use multiple comparison procedures to maintain the simultaneous probability close to the nominal significance level (typically 5%).
Multiple comparison procedures are classified by the strength of inference that can be made and the error rate controlled. A test of homogeneity controls the probability of falsely declaring any pair to be different when in fact all are the same. A stronger level of inference is confident inequalities and confident directions which control the probability of falsely declaring any pair to be different regardless of the values of the others. An even stronger level is a set of simultaneous confidence intervals that guarantees that the simultaneous coverage probability of the intervals is at least 100(1-alpha)% and also have the advantage of quantifying the possible effect size rather than producing just a p-value. A higher strength inference can be used to make an inference of a lesser strength but not vice-versa. Therefore, a confidence interval can be used to perform a confidence directions/inequalities inference, but a test of homogeneity cannot make a confidence direction/inequalities inference.
The most well known multiple comparison procedures, Bonferroni and Šidák, are not multiple comparison procedures per se. Rather they are an inequality useful in producing easy to compute multiple comparison methods of various types. In most scenarios, there are more powerful procedures available. A useful application of Bonferroni inequality is when there are a small number of pre-planned comparisons. In these cases, you can use the standard hypothesis test or confidence interval with the significance level (alpha) set to the Bonferroni inequality (alpha divided by the number of comparisons).
A side effect of maintaining the significance level is a lowering of the power of the test. Different procedures have been developed to maintain the power as high as possible depending on the strength of inference required and the number of comparisons to be made. All contrasts comparisons allow for any possible contrast; all pairs forms the k*(k-1)/2 pairwise contrasts, whereas with best forms k contrasts each with the best of the others, and against control forms k-1 contrasts each against the control group. You should choose the appropriate contrasts of interest before you perform the analysis, if you decide after inspecting the data, then you should only use all contrasts comparison procedures.
A mean-mean scatter plot shows a 2-dimensional representation of the differences between many means.
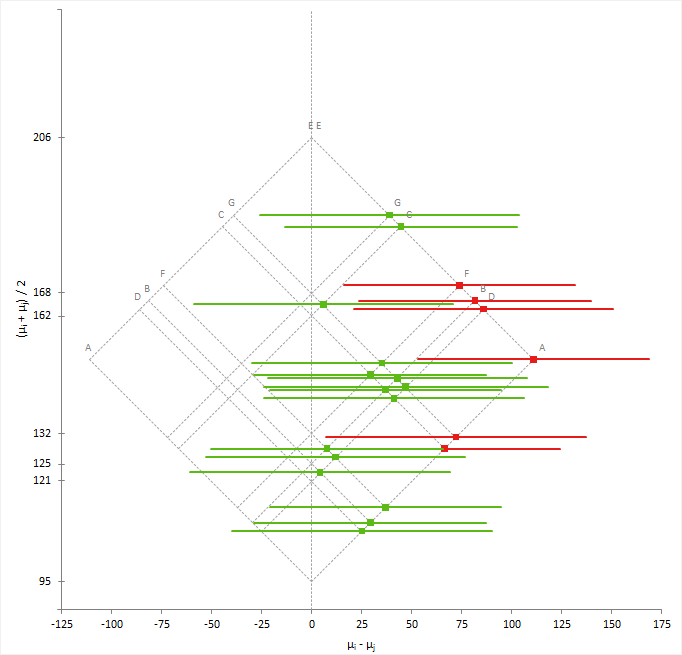
The mean-mean scatter plot shows the mean of a group on the horizontal axis against the mean of the other group on the vertical axis with a dot at the intersection. A vector centered at the intersection with a slope of -1 and a length proportional to the width of the confidence interval represents the confidence interval. A gray identity line represents equality of means; that is the difference is equal to zero. If the vector does not cross the identity line, you can conclude there is a significant difference between the means.
To make interpretation easier, a 45-degree rotated version of the plot shows the difference between means and its confidence interval on the horizontal axis against average of the means on the vertical axis.
Methods of controlling the Type I error and dependencies between parameters when making multiple comparisons between many means/medians of independent samples.
| Procedure | Purpose |
|---|---|
| Student's t (Fisher's LSD) | Compare the means of each pair of groups using the Student's t method. When making all pairwise comparisons this procedure is also known as unprotected Fisher's LSD, or when only performed following significant ANOVA F -test known as protected Fisher's LSD. Control the type I error rate is for each contrast. |
| Wilcoxon-Mann-Whitney | Compare the median/means each pair of groups using the Wilcoxon nonparametric method. Control the type I error rate for each contrast. |
| Tukey-Kramer | Compare the means of all pairs of groups using the Tukey-Kramer method. Controls the error rate simultaneously for all k(k+1)/2 contrasts. |
| Steel-Dwass-Critchlow-Fligner | Compare the median/means of all pairs of groups using the
Steel-Dwass-Critchlow-Fligner pairwise ranking nonparametric method. Controls the error rate simultaneously for all k(k+1)/2 contrasts. |
| Hsu | Compare the means of all groups against the best of the other groups using the Hsu
method. Controls the error rate simultaneously for all k contrasts. |
| Dunnett | Compare the means of all groups against a control using the Dunnett
method. Controls the error rate simultaneously for all k-1 contrasts. |
| Steel | Compare the medians/means of all groups against a control using the Steel
pairwise ranking nonparametric method. Controls the error rate simultaneously for all k-1 comparisons. |
| Scheffé | Compare the means of all groups against all other groups using the Scheffé F
method. Controls the error rate simultaneously for all possible contrasts. |
| Student-Newman-Keuls (SNK) | Not implemented. As discussed in Hsu (1996) it is not a confident inequalities method and cannot be recommended. |
| Duncan | Not implemented. As discussed in Hsu (1996) it is not a confident inequalities method and cannot be recommended. |
| Dunn | Not implemented in Analyse-it version 3 onwards. Implemented in version 1. A joint-ranking nonparametric method but as discussed in Hsu (1996) it is not a confident inequalities method and cannot be recommended. Use the Dwass-Steel-Critchlow-Fligner or Steel test instead. |
| Conover-Iman | Not implemented in Analyse-it version 3 onwards. Implemented in version 2. As discussed in Hsu (1996) applying parametric methods to the rank-transformed data may not produce a confident inequalities method even if the parametric equivalent it mimics is. Use the Dwass-Steel-Critchlow-Fligner or Steel test instead. |
| Bonferroni | Not a multiple comparisons method. It is an inequality useful in producing easy to compute multiple comparisons. In most scenarios, there are more powerful procedures such as Tukey, Dunnett, Hsu. A useful application of Bonferroni inequality is when there are a small number of pre-planned comparisons. In this case, use the Student's t (LSD) method with the significance level (alpha) set to the Bonferroni inequality (alpha divided by the number of comparisons). In this scenario, it is usually less conservative than using Scheffé all contrast comparisons. |
Compare the means/medians of many independent samples.
A homogeneity hypothesis test formally tests if the populations have equal variances.
Many statistical hypothesis tests and estimators of effect size assume that the variances of the populations are equal. This assumption allows the variances of each group to be pooled together to provide a better estimate of the population variance. A better estimate of the variance increases the statistical power of the test meaning you can use a smaller sample size to detect the same difference, or detect smaller differences and make sharper inferences with the same sample size.
When the test p-value is small, you can reject the null hypothesis and conclude that the populations differ in variance.
Tests for the homogeneity of variance of independent samples and their properties and assumptions.
| Test | Purpose |
|---|---|
| F | Test if the ratio of the variances is equal to a hypothesized value. Assumes the populations are normally distributed and is extremely sensitive to departures from normality. The Levene and Brown-Forsythe tests are more robust against violations of the normality assumption than the F-test. |
| Bartlett | Test if the variances are equal. Assumes the populations are normally distributed and is extremely sensitive to departures from normality. The Levene and Brown-Forsythe tests are more robust against violations of the normality assumption than Bartlett's test. |
| Levene | Test if the variances are equal. Most powerful test for symmetric, moderate-tailed, distributions. |
| Brown-Forsythe | Test if the variances are equal. Robust against many types of non-normality. |
Test if the variances of two or more independent samples are equal.
Compare groups analysis study requirements and dataset layout.
Use a column for the response variable (Height) and a column for the factor variable (Sex); each row has the values of the variables for a case (Subject).
| Subject (optional) | Sex | Height |
|---|---|---|
| 1 | Male | 175 |
| 2 | Male | 180 |
| 3 | Male | 160 |
| 4 | Male | 190 |
| 5 | Male | 180 |
| 6 | Female | 150 |
| 7 | Female | 140 |
| 8 | Female | 160 |
| 9 | Female | 165 |
| 10 | Female | 180 |
| … | … | … |




