
Diagnostic performance evaluates the ability of a qualitative or quantitative test to discriminate between two subclasses of subjects.
Diagnostic accuracy measures the ability of a test to detect a condition when it is present and detect the absence of a condition when it is absent.
| True positive (TP) | Test result correctly identifies the presence of the condition. |
| False positive (FP) | Test result incorrectly identifies the presence of the condition when it was absent. |
| True negative (TN) | Test result correctly identifies the absence of the condition. |
| False negative (FN) | Test result incorrectly identifies the absence of the condition when it was present. |
A perfect diagnostic test can discriminate all subjects with and without the condition and results in no false positive or false negatives. However, this is rarely achievable, as misdiagnosis of some subjects is inevitable. Measures of diagnostic accuracy quantify the discriminative ability of a test.
Sensitivity and specificity are the probability of a correct test result in subjects with and without a condition, respectively.
Sensitivity (true positive fraction, TPF) measures the ability of a test to detect the condition when it is present. It is the probability that the test result is positive when the condition is present.
Specificity (true negative fraction, TNF) measures the ability of a test to detect the absence of the condition when it is not present. It is the probability that the test result is negative when the condition is absent.
Likelihood ratios are the ratio of the probability of a specific test result for subjects with the condition against the probability of the same test result for subjects without the condition.
A likelihood ratio of 1 indicates that the test result is equally likely in subjects with and without the condition. A ratio > 1 indicates that the test result is more likely in subjects with the condition than without the condition, and conversely, a ratio < 1 indicates that the test result is more likely in subjects without the condition. The larger the ratio, the more likely the test result is in subjects with the condition than without; likewise, the smaller the ratio, the more likely the test result is in subjects without than with the condition.
The likelihood ratio of a positive test result is the ratio of the probability of a positive test result in a subject with the condition (true positive fraction) against the probability of a positive test result in a subject without the condition (false positive fraction). The likelihood ratio of a negative test result is the ratio of the probability of a negative test result in a subject with the condition (false negative fraction) to the probability of a negative test result in a subject without the condition (true negative fraction).
Predictive values are the probability of correctly identifying a subject's condition given the test result.
Predictive values use Bayes' theorem along with a pre-test prior probability (such as the prevalence of the condition in the population) and the sensitivity and specificity of the test to compute the post-test probability (predictive value).
The positive predictive value is the probability that a subject has the condition given a positive test result; the negative predictive value is the probability that a subject does not have the condition given a negative test result.
Youden's J is the likelihood of a positive test result in subjects with the condition versus those without the condition. It is also the probability of an informed decision (as opposed to a random guess).
Youden's J index combines sensitivity and specificity into a single measure (Sensitivity + Specificity - 1) and has a value between 0 and 1. In a perfect test, Youden's index equals 1. It is also equivalent to the vertical distance above the diagonal no discrimination (chance) line to the ROC curve for a single decision threshold.
Estimate the sensitivity/specificity and other measures of the accuracy of a binary diagnostic test (or a quantitative test at a specific decision threshold).
You can use this task with up to two binary tests or quantitative tests at a specified decision threshold. To show the sensitivity/specificity for all possible thresholds of a quantitative test you should use ROC curves.
Compare the sensitivity and specificity of two diagnostic tests and make inferences about the differences.
ROC (receiver operating characteristic) curves show the ability of a quantitative diagnostic test to classify subjects correctly as the decision threshold is varied.
The ROC plot shows sensitivity (true positive fraction) on the horizontal axis against 1-specificity (false positive fraction) on the vertical axis over all possible decision thresholds.
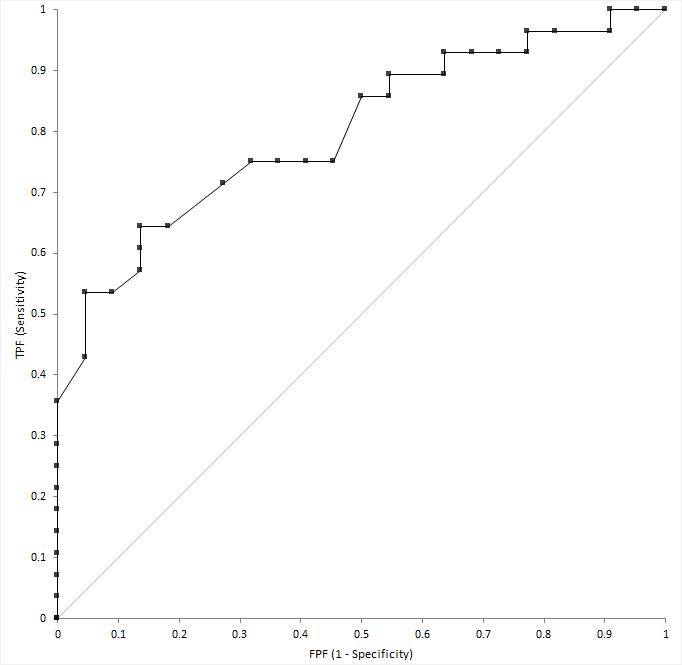
A diagnostic test able to perfectly identify subjects with and without the condition produces a curve that passes through the upper left corner (0, 1) of the plot. A diagnostic test with no ability to discriminate better than chance produces a diagonal line from the origin (0, 0) to the top right corner (1, 1) of the plot. Most tests lie somewhere between these extremes. If a curve lies below the diagonal line (0, 0 to 1, 1), you can invert it by swapping the decision criteria to produce a curve above the line.
An empirical ROC curve is the simplest to construct. Sensitivity and specificity use the empirical distributions for the subjects with and without the condition. This method is nonparametric because no parameters are needed to model the behavior of the curve, and it makes no assumptions about the underlying distribution of the two groups of subjects.
Plot the receiver-operator characteristic (ROC) curve to visualize the accuracy of a diagnostic test.
Plot multiple receiver-operator characteristics (ROC) curves to make comparisons between them.
The area under (a ROC) curve is a measure of the accuracy of a quantitative diagnostic test.
A point estimate of the AUC of the empirical ROC curve is the Mann-Whitney U estimator (DeLong et. al., 1988). The confidence interval for AUC indicates the uncertainty of the estimate and uses the Wald Z large sample normal approximation (DeLong et al., 1998). A test with no better accuracy than chance has an AUC of 0.5, a test with perfect accuracy has an AUC of 1.
AUC can be misleading as it gives equal weight to the full range of sensitivity and specificity values even though a limited range, or specific threshold, may be of practical interest.
Test if the area under the curve is better than chance, or some other value.
The difference between areas under the ROC curves compares the accuracy of two or more diagnostic tests.
It is imperative when comparing tests that you choose the correct type of analysis dependent on how you collect the data. If the tests are performed on the same subjects (paired design), the test results are usually correlated. Less commonly, you may perform the different tests on different groups of subjects or the same test on different groups of subjects, and the test results are independent. A paired design is more efficient and is preferred whenever possible.
A point estimate of the difference between the area under two curves is a single value that is the best estimate of the true unknown parameter; a confidence interval indicates the uncertainty of the estimate. If the tests are independent, the confidence interval uses the combined variance of the curves and a large sample Wald approximation. If the tests are paired, the standard error incorporates the covariance (DeLong et al., 1998) and uses a large sample Wald approximation.
The null hypothesis states that the difference is equal to zero, against the alternative hypothesis that it is not equal to zero. When the test p-value is small, you can reject the null hypothesis and conclude the difference is not equal to zero, the tests are different.
The null hypothesis states that the difference is less than a lower bound of practical equivalence or greater than an upper bound of practical equivalence, against the alternative hypothesis that the difference is within an interval considered practically equivalent. When the test p-value is small, you can reject the null hypothesis and conclude that the tests are equivalent.
The null hypothesis states that the difference from a standard test is greater than the smallest practical difference against the alternative hypothesis that the difference from the standard test is less than the smallest practical difference. When the test p-value is small, you can reject the null hypothesis and conclude that the test is not inferior to the standard test.
When the ROC curves cross, the difference between the AUC does not provide much useful information.
Test if the area under curves is equal, equivalent, or not inferior to another.
A decision threshold is a value that dichotomizes the result of a quantitative test to a simple binary decision.
The test result of a quantitative diagnostic test is dichotomized by treating the values above or equal to a threshold as positive, and those below as negative, or vice-versa.
There are many ways to choose a decision threshold for a diagnostic test. For a simple screening test, the decision threshold is often chosen to incur a fixed, true positive, or false positive rate. In more complex cases, the optimal decision threshold depends on both the cost of performing the test and the cost of the consequences of the test result. The costs may include both financial and health-related costs. A simple formula to determine the optimal decision threshold (Zweig & Campbell, 1993) maximizes: Sensitivity - m * (1- Specificity) where m = (Cost FP - Cost TN) / (Cost FN - Cost TP).
A decision plot shows a measure of performance (such as sensitivity, specificity, likelihood ratios, or predictive values) against all decision thresholds to help identify optimal decision threshold.
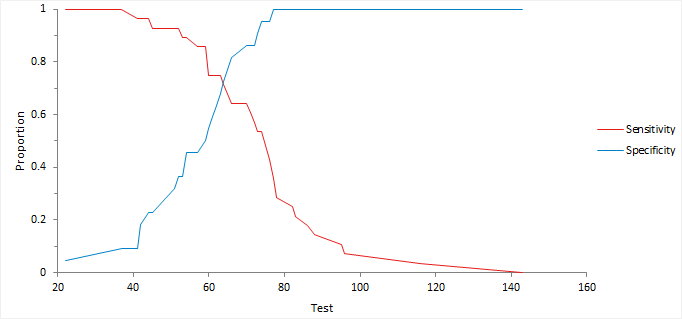
Find the optimal decision threshold using information on the relative costs of making correct and incorrect decisions.
Predict the threshold for a fixed true/false positive rate.
Diagnostic performance study requirements and dataset layout.
Use a column for the true state variable (State), and a column for the test measured values (Test); each row has the values of the variables for a case (Subject).
| Subject (optional) | State | Test |
|---|---|---|
| 1 | Diseased | 121 |
| 2 | Diseased | 118 |
| 3 | Diseased | 124 |
| 4 | Diseased | 120 |
| 5 | Diseased | 116 |
| 6 | … | … |
| 7 | Healthy | 100 |
| 8 | Healthy | 115 |
| 9 | Healthy | 102 |
| 10 | Healthy | 98 |
| 11 | Healthy | 118 |
| … | … | … |
Use a column for the true state variable (State), and a column for each of the test measured values (Test 1, Test 2); each row has the values of the variables for a case (Subject).
| Subject (optional) | State | Test 1 | Test 2 |
|---|---|---|---|
| 1 | Diseased | 121 | 86 |
| 2 | Diseased | 118 | 90 |
| 3 | Diseased | 124 | 91 |
| 4 | Diseased | 120 | 99 |
| 5 | Diseased | 116 | 89 |
| 6 | … | … | … |
| 7 | Healthy | 100 | 70 |
| 8 | Healthy | 115 | 80 |
| 9 | Healthy | 102 | 79 |
| 10 | Healthy | 98 | 87 |
| 11 | Healthy | 118 | 90 |
| … | … | … |
Use a column for the true state variable (State), a column for the factor (test or group indicator), and a column for the test measured values (Test); each row has the values of the variables for a case (Subject).
| Subject (optional) | State | Test/Group ID | Test result |
|---|---|---|---|
| 1 | Diseased | 1 | 121 |
| 2 | Diseased | 1 | 118 |
| 3 | Diseased | 1 | 124 |
| 4 | Diseased | 1 | 120 |
| 5 | Diseased | 1 | 116 |
| 6 | Healthy | 1 | 100 |
| 7 | Healthy | 1 | 115 |
| 8 | Healthy | 1 | 102 |
| 9 | Healthy | 1 | 98 |
| 10 | Healthy | 1 | 118 |
| 11 | … | … | … |
| 12 | Diseased | 2 | 86 |
| 13 | Diseased | 2 | 90 |
| 14 | Diseased | 2 | 91 |
| 15 | Diseased | 2 | 99 |
| 16 | Diseased | 2 | 89 |
| 17 | Healthy | 2 | 70 |
| 18 | Healthy | 2 | 80 |
| 19 | Healthy | 2 | 79 |
| 20 | Healthy | 2 | 87 |
| 21 | Healthy | 2 | 90 |
| … | … | … | … |
Use a column for the true state variable (State), and a column for the test indications (Test); each row has the values of the variables for a case (Subject).
| Subject (optional) | State | Test |
|---|---|---|
| 1 | Diseased | P |
| 2 | Diseased | P |
| 3 | Diseased | P |
| 4 | Diseased | N |
| 5 | Diseased | P |
| 6 | Healthy | N |
| 7 | Healthy | N |
| 8 | Healthy | N |
| 9 | Healthy | N |
| 10 | Healthy | N |
| … | … | … |
Use a column for the true state variable (State), and a column for the test indications (Test) and a column for the number of cases (Frequency); each row has the values of the variables and the frequency count.
| State | Test | Count |
|---|---|---|
| Diseased | Positive | 3 |
| Diseased | Negative | 1 |
| Healthy | Positive | 0 |
| Healthy | Negative | 5 |
Use a column for the true state variable (State), a column for the factor (test or group indicator), a column for the test indications (Test) and a column for the number of cases (Frequency); each row has the values of the variables and the frequency count.
| State | Test | Group/Test ID | Count |
|---|---|---|---|
| Diseased | Positive | 1 | 3 |
| Diseased | Negative | 1 | 1 |
| Healthy | Positive | 1 | 0 |
| Healthy | Negative | 1 | 5 |
| Diseased | Positive | 2 | 24 |
| Diseased | Negative | 2 | 2 |
| Healthy | Positive | 2 | 2 |
| Healthy | Negative | 2 | 30 |
Use a column for the true state variable (State), a column for each of the test indications (Test 1, Test 2) and a column for the number of cases (Frequency); each row has the values of the variables and the frequency count.
| State | Test 1 | Test 2 | Count |
|---|---|---|---|
| Diseased | Positive | Positive | 3 |
| Diseased | Negative | Positive | 1 |
| Diseased | Positive | Negative | 24 |
| Diseased | Negative | Negative | 2 |
| Healthy | Positive | Positive | 0 |
| Healthy | Negative | Positive | 5 |
| Healthy | Positive | Negative | 2 |
| Healthy | Negative | Negative | 30 |


