
A reference interval (sometimes called a reference range or normal range) describes the range of values of a measured quantity in healthy individuals.
A reference limit defines a value where a given proportion of reference values are less than or equal to. A reference interval defines the interval between a lower and upper reference limit that includes a given proportion of the reference values.
The process of defining a reference interval is that reference individuals compromise a reference population from which is selected a reference sample group on which are determined reference values on which is observed a reference distribution from which are calculated reference limits that define a reference interval.
A point estimate of a reference limit is a single value that is the best estimate of the true unknown parameter; a confidence interval is a range of values and indicates the uncertainty of the estimate. It is important to remember that the width of the confidence interval is dependent upon sample size and that large sample sizes are required to produce narrow confidence intervals, particularly for skewed distributions (Linnet, 2000).
There are numerous quantile estimators that may define the reference limits. The best estimator depends heavily on the shape of the distribution.
A quantile estimator derived from a normally distributed population with unknown mean and standard deviation.
A normal theory quantile is most powerful when a random sample is from a population with a normal distribution.
| Estimator | Description |
|---|---|
| MVUE | The uniformly minimum unbiased variance quantile estimator uses the sample mean and unbiased standard deviation as the best estimate of the population parameters (Xbar ± Z(alpha) * (s / c4(n))). The factor c4(n) is applied to the sample standard deviation to account for the bias in the estimate for small sample sizes. |
| t-based | The t-based prediction interval quantile estimator uses the Student's t distribution for a prediction interval (Xbar ± t(alpha, n-1) * s * sqrt(1+1/n)) for a single future observation (Horn, 2005). Note that this method produces a wider interval than the MVUE estimator for small samples. |
In many cases, the data are skewed to the right and do not follow a normal distribution. A Box-Cox (or logarithmic) transform can correct the skewness, allowing you to use the Normal theory quantile. If not, a distribution-free estimator may be more powerful (IFCC, 1987).
A distribution-free (non-parametric) quantile estimator based on the order statistics (the sorted values in the sample).
There are several definitions for the quantile estimator useful in defining reference limits.
| Formula (N is the sample size and p is the quantile) | Description |
|---|---|
| Np+1/2 | Piecewise linear function where the knots are the values midway through the steps of the empirical distribution function. Recommended by Linnet (2000) as having the lowest root-mean-squared-error . |
| (N+1)p | Linear interpolation of the expectations for the order statistics of the uniform distribution on [0,1]. Recommended by IFCC (1987) and CLSI (2010). |
| (N+1/3)p+1/3 | Linear interpolation of the approximate medians for the order statistics. Has many excellent properties and is approximately median-unbiased regardless of the distribution. |
A 95% reference interval (0.025 and 0.975 quantiles) requires a minimum sample size of 39. A 90% confidence interval for a 95% reference interval requires a minimum sample size of 119.
A distribution-free (non-parametric) quantile estimator that is the median of a set of quantiles calculated by re-sampling the original sample a large number of times and computing a quantile for each sample.
The bootstrap quantile (Linnet, 2000)as providing the lowest root-mean-squared-error (an estimate of the bias and precision in the estimate) for both normal and skewed distributions. Another advantage is that confidence intervals can be computed for smaller sample sizes, although Linnet still recommends a sample size of at least 100.
A distribution-free (non-parametric) estimator that is a weighted linear combination of order statistics. It is substantially more efficient than the traditional estimator based on one or two order statistics.
A quantile estimator that uses robust estimators of location and spread, which resist the effects of extreme observations.
The robust bi-weight estimator (Horn & Pesce 1998) uses robust estimators of location and spread, which resist the effects of extreme observations. It requires a symmetric distribution. If the distribution is skewed, you should apply a transform to achieve symmetry, or create a new sample by mirroring the sample around the median to form a symmetric distribution (Horn, 1990), before applying the bi-weight estimator.
Estimate the reference limit or reference interval using a quantile estimator.
A histogram shows the distribution of the data to assess the central tendency, variability, and shape.
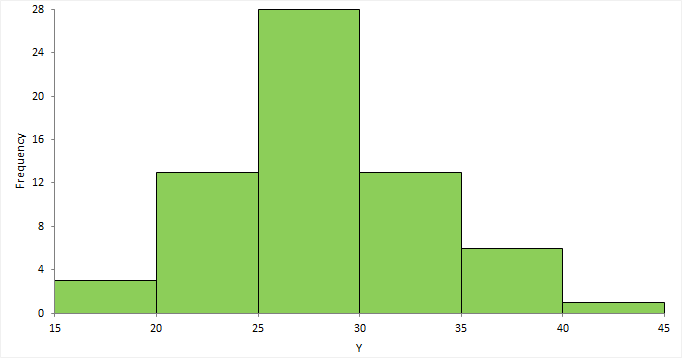
A histogram for a quantitative variable divides the range of the values into discrete classes, and then counts the number of observations falling into each class interval. The area of each bar in the histogram is proportional to the frequency in the class. When the class widths are equal, the height of the bar is also proportional to the frequency in the class.
Choosing the number of classes to use can be difficult as there is no "best," and different class widths can reveal or hide features of the data. Scott's and Freedman-Diaconis' rules provide a default starting point, though sometimes particular class intervals make sense for a particular problem.
The histogram reveals if the distribution of the data is normal, skewed (shifted to the left or right), bimodal (has more than one peak) and so on. Skewed data can sometimes be transformed to normal using a transformation. Bi-modality often indicates that there is more than one underlying population in the data. Individual bars distanced from the bulk of the data can indicate the presence of an outlier.
A box plot shows the five-number summary of the data – the minimum, first quartile, median, third quartile, and maximum. An outlier box plot is a variation of the skeletal box plot that also identifies possible outliers.
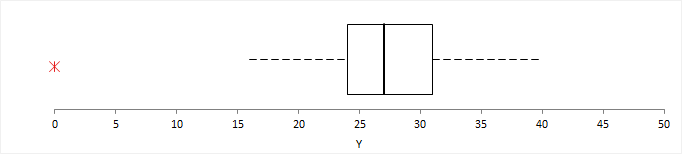
An outlier box plot is a variation of the skeletal box plot, but instead of extending to the minimum and maximum, the whiskers extend to the furthest observation within 1.5 x IQR from the quartiles. Possible near outliers (orange plus symbol) are identified as observations further than 1.5 x IQR from the quartiles, and possible far outliers (red asterisk symbol) as observations further than 3.0 x IQR from the quartiles. You should investigate each possible outlier before deciding whether to exclude it, as even in normally distributed data, an outlier box plot identifies approximately 0.7% of observations as possible outliers.
A normal probability plot, or more specifically a quantile-quantile (Q-Q) plot, shows the distribution of the data against the expected normal distribution.
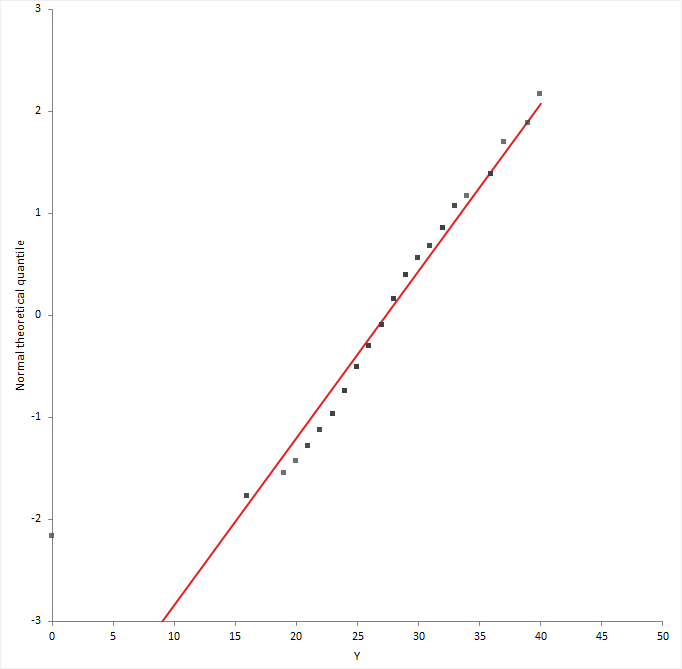
For normally distributed data, observations should lie approximately on a straight line. If the data is non-normal, the points form a curve that deviates markedly from a straight line. Possible outliers are points at the ends of the line, distanced from the bulk of the observations.
Test if a reference distribution is normal.
Transform the reference values to achieve a normal distribution.
You should transform the data when the distribution does not match the assumptions of the quantile estimator. If you cannot transform the distribution to meet the assumptions of the estimator you should consider using another estimator.
Transfer a reference limit or reference interval from one method or laboratory to another.
Reference interval study requirements and dataset layout.
Use a column for the variable (Reference value), and optionally additional columns for each partition factor (Sex); each row has the values of the variables for a case (Subject).
| Subject (optional) | Sex (optional) | Reference value |
|---|---|---|
| 1 | Male | 121 |
| 2 | Male | 118 |
| 3 | Female | 124 |
| 4 | Female | 120 |
| 5 | Male | 116 |
| 6 | Male | … |
| 7 | Female | 100 |
| 8 | Male | 115 |
| 9 | Female | 102 |
| 10 | Female | 98 |
| 11 | Male | 118 |
| … | … | … |


